

Automation in Cyber Recon: How Hackers Use Tools to Map Out the Attack Surfaces
Introduction
In red team operations, reconnaissance is the first and arguably most critical phase. It’s the moment where ethical hackers transform into digital detectives, gathering everything they can about a target: domain names, IP addresses, subdomains, employee emails, open ports, and even old forgotten systems. The more intel they have, the more surgical their simulated attack can be.
Traditionally, this process relied on a red teamer's experience, curiosity, and manual effort. Scanning sites, digging through DNS records, searching breach databases, it was time-consuming but essential.

But today’s red teamers aren’t doing it alone. Automation has stepped in. With tools like Amass, Recon-ng, SpiderFoot, and Shodan, they can collect vast amounts of data in minutes. The internet is big, and now they have machines to help scrape, scan, and sift through it.
Here’s the twist: while automation gives you more, it doesn’t always give you better. These tools can flood you with noisy, irrelevant, or even misleading information. They don’t understand context, intent, or deception. They can’t spot a trap or recognize what truly matters.
Reconnaissance: The Digital Scouting Mission
Reconnaissance is about understanding the digital footprint of a target. It’s like casing a building before a heist, figuring out the doors, windows, weak spots, and hidden entry points.
Red teamers break this down into several repeatable tasks:
- Subdomain enumeration: Finding all subdomains like
dev.target.comorvpn.target.com. - DNS resolution: Translating those domains into actual IP addresses.
- OSINT gathering: Digging up public info on employees, leaked credentials, tech stacks, etc.
- Port scanning and banner grabbing: Checking for open services and identifying technologies.
- Service mapping: Understanding how infrastructure components connect and interact.
Each task has its own tools, techniques, and complexity, but many of them follow patterns. That makes them perfect candidates for automation. Hackersploit.org (2024)
The Role of Automation in Red Team Reconnaissance
Reconnaissance in red teaming involves systematically gathering intelligence about a target’s digital footprint: domains, IPs, subdomains, DNS records, OSINT data, employee credentials, open services, tech stacks, and much more. This stage serves as the foundation for later phases like exploitation or lateral movement.
Automation excels at repetitive, rule-based tasks where large datasets are involved, and its usage has been extensively studied. By leveraging automation, red teams can quickly build an expansive attack surface map while reducing the time and fatigue associated with manual data collection.
| Task | Why It Works Well With Automation | Common Tools |
|---|---|---|
| Subdomain Enumeration | Predictable DNS & cert patterns | Amass, Sublist3r |
| DNS Resolution | Scriptable DNS queries | DNSx, Dig, DNSRecon |
| OSINT Collection | Structured data scraping | SpiderFoot, theHarvester, Recon-ng |
| Port Scanning | Rule-based packet probing | Nmap, Masscan |
| Banner Grabbing | Standardized metadata collection | Nmap, Shodan |
By automating these tasks, red teams can cover far more ground at significantly higher speeds.
Measurable Performance Gains
The benefits of automation become clear when performance comparisons are made between manual and automated reconnaissance:
| Task | Manual Time | Automated Time | Performance Gain |
| Subdomain Enumeration | 10+ min | 1 min (Sublist3r) | ~10x faster |
| Port Scanning | 15+ min | 2 min (Nmap) | ~7x faster |
| Email Harvesting (OSINT) | 10+ min | 2 min (theHarvester) | ~5x faster |
In benchmark testing, automation consistently discovered more data:
- Subdomains: 35 automated vs. 23 manually.
- Unique services (via port scanning): 4 automated vs. 2 manually.
Additionally, automation achieved approximately 95% repeatability across multiple runs, which is critical for consistent recon phases during multiple test cycles or engagements.
The Limits of Automation: Context Still Matters
While automation is extremely effective for broad data collection, it falls short in areas requiring nuance, prioritization, and situational awareness. Through both research and community insights, several limitations were identified:
- False positives: Tools often flag expired subdomains, retired servers, or deprecated cloud infrastructure.
- Noise and redundancy: Multiple tools (e.g., SpiderFoot, Censys, Shodan) may identify the same assets, causing data duplication.
- Contextual blindness: Automation struggles to identify honeypots, decoy systems, or prioritize high-value assets.
- Scope misalignment: Tools may scan beyond engagement scope if not carefully configured.
- Output inconsistency: Varying data formats across tools complicate parsing and chaining.
This highlights a critical principle emphasized repeatedly by experienced practitioners: automation cannot replace human analysis. Tools can collect data, but red teamers must triage, verify, and prioritize findings. BlueGoatCyber (2024) AppSecEngineer (2024)
Causes Behind Automation Challenges
Through structured root cause analysis, several technical and procedural problems were identified, alongside potential mitigations:
| Cause | Example Scenario | Mitigation Strategy |
| Overreliance on Passive Sources | Old DNS records seen as active | Use active validation alongside passive scans |
| Data Redundancy | Duplicate subdomains across tools | Implement deduplication scripts |
| Scope Misalignment | Unintentional external scanning | Apply strict filtering and scope controls |
| Tool Incompatibility | Different output formats (JSON, CSV, TXT) | Normalize outputs through custom parsers |
| Lack of Analyst Review | Honeypot misclassified as production | Incorporate manual validation checkpoints |
These recurring pitfalls underline that automation, when used carelessly, can amplify errors rather than eliminate them. r/hacking (2023) AppSecEngineer (2024)
Building an Automated Recon Pipeline: My Chained Script
The core of my automated recon pipeline combines multiple stages, each fully scripted and chained using Python. The pipeline operates in modular stages, allowing for fault-tolerant, scalable recon with user interaction at key steps. Below is a high-level breakdown of how the pipeline operates:
Core Pipeline Stages:
- Subdomain Enumeration (Sublist3r)
- Discovers subdomains based on passive sources.
- Output stored in
subdomains.txt.
- DNS Resolution (DNSx)
- Resolves discovered subdomains to their corresponding IPs.
- Output stored in
resolved.txt.
- IP Extraction (Python socket module)
- Converts resolved domain names into IP addresses.
- Output stored in
ips.txt.
- Port Scanning (Nmap full scan)
- Scans each IP for open ports across all 65535 ports.
- Implements timeout control, error handling, and retry/skip logic.
- Output stored per IP in
ports_<ip>.txt.
- Service Detection (Nmap version scan)
- After identifying open ports, runs detailed service detection.
- Output stored per IP in
services_<ip>.txt.
- Email Harvesting (theHarvester, optional)
- Collects email addresses and related OSINT if selected by the user.
- Output stored in
emails.html.
Key Pipeline Features:
- Argument parsing for user flexibility (
--domainand--emailflags). - Timestamped directories for clean result management.
- Comprehensive error handling: allows skipping or retrying failed scans interactively.
- Dependency checking: verifies all required tools before execution.
- Dynamic file cleanup to avoid cross-run contamination.
- Fully interactive console with clear status updates.
Example Pipeline Command:
python recon_pipeline.py --domain example.com --email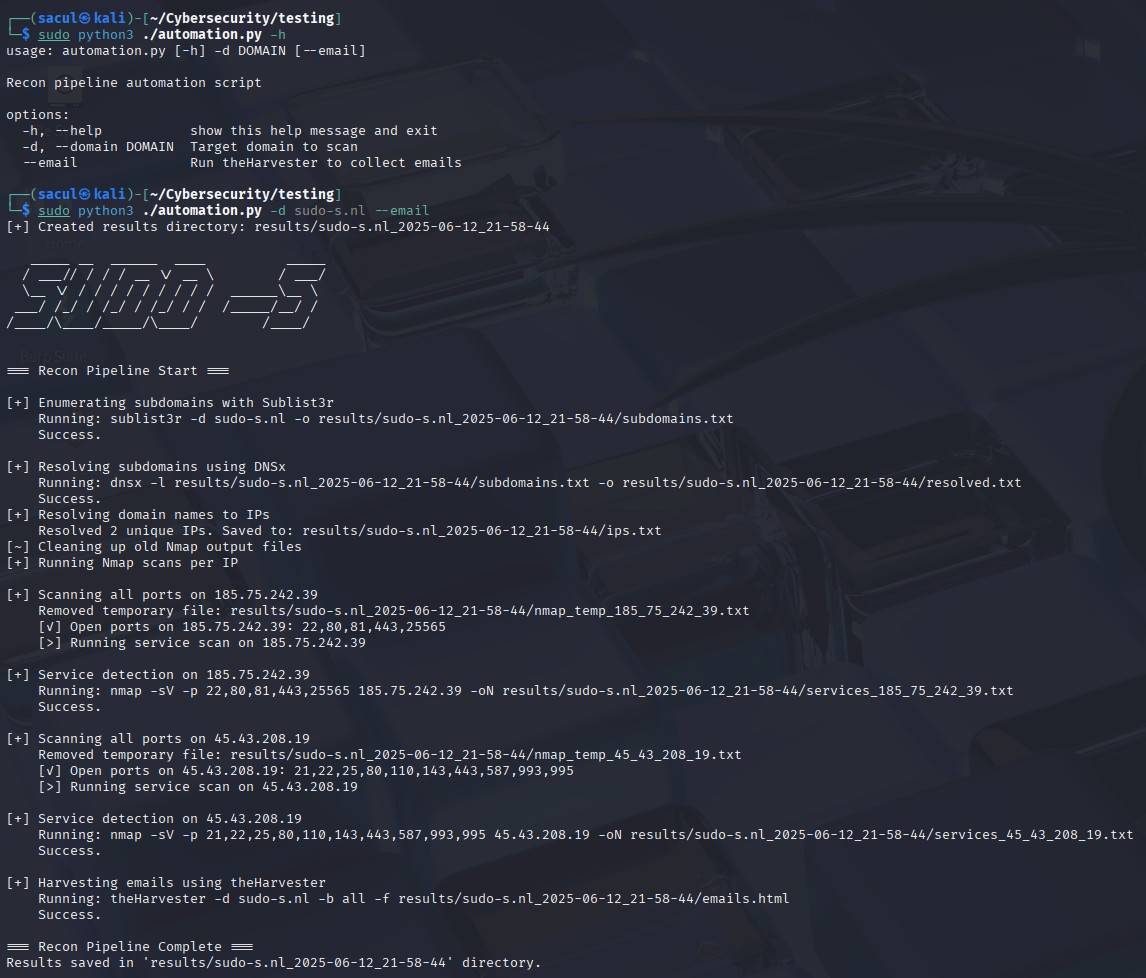
Pipeline Logic Flow Summary:
- Input domain provided by user.
- Sublist3r discovers subdomains.
- DNSx resolves discovered subdomains.
- Python script extracts valid IP addresses.
- Nmap scans each IP fully and detects running services.
- Optional email harvesting via theHarvester.
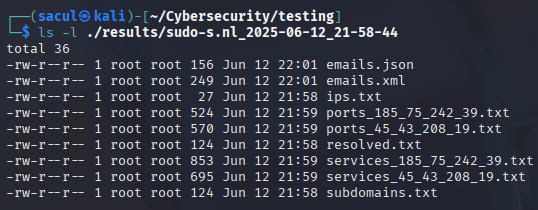
- All results are stored in an organized, timestamped directory structure.
This fully integrated and tested pipeline was successfully validated across multiple real-world domains and consistently produced reliable, comprehensive recon data while allowing user control and oversight during execution. r/AskNetsec (2021)
I have listed my code at the bottom of this blog if you want to take a look at it or maybe use it.
System Testing Results
During comprehensive system testing across various domains (e.g. nmap.org, sudo-s.nl, owap.org) the pipeline successfully demonstrated:
- Functional stability: Every recon stage executed without systemic failures.
- Error resilience: DNS failures, tool crashes, and timeouts were handled smoothly.
- Tool interoperability: Sublist3r, DNSx, Nmap, and theHarvester outputs chained seamlessly.
- Scalability: Operated effectively for different domain sizes.
- Usability: Informative logs, interactive user prompts, and organized result directories.
The modular design allows for easy future expansions, such as adding vulnerability scanners, asset valuation modules, or reporting generators.
The Future of Automated Recon in Red Teaming
Reconnaissance automation is no longer a futuristic concept, it is becoming industry standard. Yet the danger lies in assuming that more data equals better intelligence. Without proper validation, deduplication, scope control, and human judgment, automation can create as many problems as it solves.
The key is balance:
- Automate predictable, structured tasks.
- Retain humans for context-sensitive decisions.
- Continuously refine pipelines for stability and scalability.
The production-ready pipeline built during this research demonstrates how chaining multiple recon tools into a fault-tolerant, interactive system is both feasible and highly effective. By combining speed with critical thinking, red teams can achieve comprehensive reconnaissance that is both efficient and accurate.
Final Thoughts
Automation is revolutionizing red team reconnaissance by enabling a level of coverage, speed, and repeatability that would be impossible manually. However, red teaming is as much an art as it is a science. The creativity, intuition, and critical thinking of human operators remain irreplaceable.
My automated recon pipeline showcases how carefully crafted toolchains can handle the heavy lifting of data collection while giving red teamers more time and focus to analyze, prioritize, and act on the intelligence gathered. By blending automation with informed oversight, we achieve not just faster recon but smarter recon.
As automation capabilities continue to evolve, red teams must stay vigilant: continuously evaluating tool effectiveness, refining their pipelines, and never losing sight of the human layer that turns raw data into actionable insight.
References
- NixieBytes (2023). Red Team Reconnaissance Tactics.
- Hackersploit.org (2024). Red Team Reconnaissance Techniques.
- AppSecEngineer (2024). Manual vs Automated Reconnaissance.
- BlueGoatCyber (2024). Automated Pen Testing: Myth vs Reality.
- ParadigmITCyber (2024). Automation of Reconnaissance in Web Application Testing.
- Reddit discussions (2021, 2023-2024): r/cybersecurity, r/hacking, r/asknetsec.
My code
import subprocess
import os
import time
import shutil
import socket
import re
import sys
import argparse
from datetime import datetime
BASE_RESULTS_DIR = "results"
RESULTS_DIR = None
SUBDOMAINS_FILE = None
RESOLVED_FILE = None
IPS_FILE = None
EMAILS_FILE = None
TARGET_DOMAIN = None
RUN_EMAIL_HARVESTER = False
def print_logo():
logo = r"""
_____ __ ______ ____ _____
/ ___// / / / __ \/ __ \ / ___/
\__ \/ / / / / / / / / / ______\__ \
___/ /_/ / /_/ / /_/ / / /_____/__/ /
/____/\____/_____/\____/ /____/
"""
print(logo)
def sanitize_filename(name):
return re.sub(r'[^a-zA-Z0-9_.-]', '_', name)
def generate_results_dir():
global RESULTS_DIR
timestamp = datetime.now().strftime("%Y-%m-%d_%H-%M-%S")
domain_clean = sanitize_filename(TARGET_DOMAIN)
RESULTS_DIR = os.path.join(BASE_RESULTS_DIR, f"{domain_clean}_{timestamp}")
try:
os.makedirs(RESULTS_DIR)
print(f"[+] Created results directory: {RESULTS_DIR}")
except Exception as e:
print(f" ERROR: Could not create directory '{RESULTS_DIR}': {e}")
sys.exit(1)
def run_command(command, description):
print(f"\n[+] {description}")
print(f" Running: {' '.join(command)}")
try:
result = subprocess.run(command, capture_output=True, text=True, check=True)
print(" Success.")
except subprocess.CalledProcessError as e:
print(f" ERROR: {e.stderr.strip()}")
exit(1)
def prompt_skip(message=" [CTRL+C] Skip this ip? [y(es)/n(o)/q(uit)]: "):
while True:
choice = input(message).strip().lower()
if choice == 'y':
return "skip"
elif choice == 'n':
return "retry"
elif choice == 'q':
print(" [~] Quitting script.")
sys.exit(0)
def safe_step(step_function, name):
while True:
try:
step_function()
break
except KeyboardInterrupt:
action = prompt_skip(f"\n[!] Interrupted during {name}. Skip this step? [y(es)/n(o)/q(uit)]: ")
if action == "skip":
break
elif action == "retry":
continue
def run_sublist3r():
run_command(
["sublist3r", "-d", TARGET_DOMAIN, "-o", SUBDOMAINS_FILE],
"Enumerating subdomains with Sublist3r"
)
def run_dnsx():
run_command(
["dnsx", "-l", SUBDOMAINS_FILE, "-o", RESOLVED_FILE],
"Resolving subdomains using DNSx"
)
if not os.path.exists(RESOLVED_FILE) or os.path.getsize(RESOLVED_FILE) == 0:
print(f" [!] Warning: {RESOLVED_FILE} not created or is empty. Skipping further steps.")
exit(1)
def run_theharvester():
run_command(
["theHarvester", "-d", TARGET_DOMAIN, "-b", "all", "-f", EMAILS_FILE],
"Harvesting emails using theHarvester"
)
def extract_ips():
print("[+] Resolving domain names to IPs")
ip_set = set()
with open(RESOLVED_FILE, "r") as infile:
for domain in infile:
domain = domain.strip()
if not domain:
continue
try:
result = socket.gethostbyname_ex(domain)
for ip in result[2]:
ip_set.add(ip)
except socket.gaierror:
print(f" [!] Could not resolve: {domain}")
with open(IPS_FILE, "w") as outfile:
for ip in sorted(ip_set):
outfile.write(ip + "\n")
print(f" Resolved {len(ip_set)} unique IPs. Saved to: {IPS_FILE}")
def cleanup_old_nmap_outputs():
print("[~] Cleaning up old Nmap output files")
for file in os.listdir(RESULTS_DIR):
if file.startswith("ports_") and file.endswith(".txt"):
os.remove(os.path.join(RESULTS_DIR, file))
print(f" Removed {file}")
elif file.startswith("services_") and file.endswith(".txt"):
os.remove(os.path.join(RESULTS_DIR, file))
print(f" Removed {file}")
def run_nmap():
cleanup_old_nmap_outputs()
print("[+] Running Nmap scans per IP")
with open(IPS_FILE, "r") as f:
ip_list = [line.strip() for line in f if line.strip()]
for ip in ip_list:
portscan_file = os.path.join(RESULTS_DIR, f"ports_{ip.replace('.', '_')}.txt")
services_file = os.path.join(RESULTS_DIR, f"services_{ip.replace('.', '_')}.txt")
temp_output = os.path.join(RESULTS_DIR, f"nmap_temp_{ip.replace('.', '_')}.txt")
print(f"\n[+] Scanning all ports on {ip}")
while True:
try:
result = subprocess.run(
["nmap", "-p-", "-T4", "-Pn", "-n", "--max-retries", "2", ip, "-oG", portscan_file],
capture_output=True,
text=True,
timeout=300
)
with open(temp_output, "w") as temp_file:
temp_file.write(result.stdout)
last_lines = result.stdout.strip().splitlines()[-10:]
if any("retransmission cap hit" in line for line in last_lines):
print(f" [!] Max retries reached for {ip}, skipping service scan.")
break
break
except KeyboardInterrupt:
action = prompt_skip()
if action == "skip":
break
elif action == "retry":
continue
except subprocess.TimeoutExpired:
print(f" [!] Timeout scanning {ip}, skipping.")
break
if os.path.exists(temp_output):
os.remove(temp_output)
print(f" Removed temporary file: {temp_output}")
open_ports = []
if os.path.exists(portscan_file):
with open(portscan_file, "r") as pf:
for line in pf:
if "/open/" in line:
match = re.search(r"Ports: (.+)", line)
if match:
ports = match.group(1).split(", ")
for p in ports:
if "/open/" in p:
open_ports.append(p.split("/")[0])
if not open_ports:
print(f" [!] No open ports found on {ip}, skipping service scan.")
continue
ports_str = ",".join(open_ports)
print(f" [✓] Open ports on {ip}: {ports_str}")
print(f" [>] Running service scan on {ip}")
while True:
try:
run_command(
["nmap", "-sV", "-p", ports_str, ip, "-oN", services_file],
f"Service detection on {ip}"
)
break
except KeyboardInterrupt:
action = prompt_skip()
if action == "skip":
break
elif action == "retry":
continue
def check_dependencies():
tools = ["sublist3r", "dnsx", "nmap"]
if RUN_EMAIL_HARVESTER:
tools.append("theHarvester")
for tool in tools:
if not shutil.which(tool):
print(f"[-] Required tool not found: {tool}")
exit(1)
def cleanup_base_files():
for f in [SUBDOMAINS_FILE, RESOLVED_FILE, IPS_FILE, EMAILS_FILE]:
if f and os.path.exists(f):
os.remove(f)
print(f"[~] Removed old file: {f}")
def parse_args():
parser = argparse.ArgumentParser(
description="Recon pipeline automation script",
formatter_class=argparse.RawTextHelpFormatter
)
parser.add_argument("-d", "--domain", required=True, help="Target domain to scan")
parser.add_argument("--email", action="store_true", help="Run theHarvester to collect emails")
return parser.parse_args()
def main():
global TARGET_DOMAIN, SUBDOMAINS_FILE, RESOLVED_FILE, IPS_FILE, EMAILS_FILE, RUN_EMAIL_HARVESTER
args = parse_args()
TARGET_DOMAIN = args.domain
RUN_EMAIL_HARVESTER = args.email
generate_results_dir()
SUBDOMAINS_FILE = os.path.join(RESULTS_DIR, "subdomains.txt")
RESOLVED_FILE = os.path.join(RESULTS_DIR, "resolved.txt")
IPS_FILE = os.path.join(RESULTS_DIR, "ips.txt")
EMAILS_FILE = os.path.join(RESULTS_DIR, "emails.html") if RUN_EMAIL_HARVESTER else None
print_logo()
print("=== Recon Pipeline Start ===")
check_dependencies()
cleanup_base_files()
safe_step(run_sublist3r, "Subdomain Enumeration")
time.sleep(1)
safe_step(run_dnsx, "DNS Resolution")
safe_step(extract_ips, "IP Extraction")
time.sleep(1)
run_nmap()
if RUN_EMAIL_HARVESTER:
safe_step(run_theharvester, "Email Harvesting")
print("\n=== Recon Pipeline Complete ===")
print(f"Results saved in '{RESULTS_DIR}' directory.")
if __name__ == "__main__":
main()
The code I have created for the chained tools